Another year has come to pass, and it’s time for some more reflection! Despite its many flaws, the (only? :s) one way this year has been a successful one is through all the code I’ve managed to write. So without delving more into all the melancholy, let’s jump right in on what really matters in life and think of all the great projects I’ve had:
I started the year with embedded development in C#, then did two intensive months of game development - starting by learning Vulkan and ray tracing from scratch, learned Kubernetes and Terraform, a bit of cloud, worked on my homepage, and then did a bit more of embedded stuff by writing some programs to monitor and control factories in Minecraft.
Embedded .NET with Meadow
For the first half of the year I got back to embedded development and managed to drastically improve the UX and reliability of setting short timers. This is all thanks to the Meadow platform having reached a much better maturity compared to how it was the year or two before, when I first started working on it. I even wrote a post about the adventures I had when designing and implementing that system. There’s also a short Youtube clip illustrating how it’s all used in my daily life. At that point I was feeling really good having “shipped” something useful, and moved on to the next topic. Before this (for many many years) I had used the same launcher, but the countdowns were opened to a browser window.
Plus, over time I’ve gotten really used to the system, and thought that I couldn’t ever live without it. This assumption was however challenged a month or two ago, when I upgraded the firmware on the device running the display hardware, instead of the other device I was supposed to develop serial port things on. But what the hell. Let’s just upgrade it to the new OS and get all the promised stability and performance upgrades while at it. Maybe those would even eliminate the very rare restarts when a watchdog timer set by me times out.
One of the big new features of that new release was the inclusion of a new linker, which is able to trim out unused code, greatly reducing both the code size and the startup speed. Unfortunately, this specific linker isn’t implemented the same way as the one by Microsoft in the full .NET SDK, and there seems to be no working developer-facing options to alter its behaviour yet - it's all beta. The way it’s currently implemented strips out code needed by reflection-based serialization, leaving me stranded with my API calls.
One could think that I could always go back to the old OS, but the matter has two obstacles. The first being the tooling, as it is still under active development, and there’s no apparent way to install a previous version. Though I highly doubt it’s been blocked yet, and there’s a responsive Slack channel to ask about these things. But the second one is quite embarrassing. The last time I worked on the codebase, it was when I moved the server side stuff to my Kubernetes server (more on that later), and it turned out to be a more involved operation than originally foreseen.
When I finally got it to work, I was rather frustrated, and seemed to have forgotten to make the final commit - but there’s really no excuse for this kind of irresponsible behaviour. So after I had done the OS update and the code updates to go with it, I no longer had a working version to go back to. Rather than taking the time to fix things, I’ll just have to live with my mistakes until the new OS is at a serviceable state. At least I’ve had plenty of things to keep me busy and not thinking about it. Quite the theme overall…
Vulkan and ray tracing
The timing for my next expedition couldn’t have been better. After I had neatly finished the work on the timer (but before the OS update), there was a bit of time to relax. How unheard of. When it was time for my summer holiday, I was already anxious to try something new. For a long time I’d been meaning to learn Vulkan, and now I also had the spirit and the time for it. And not just Vulkan, if things would progress well.
I think it took me about a week to go through most of the tutorial. I had originally anticipated it to take the whole month, so my spirit was further elevated by that triumph! As detailed in the relevant post, one of my long-lived dreams has been to build a game with realtime soft shadows. I’ve always thought the math for it to be beyond my abilities - except now. Armed with Vulkan and powerful hardware, perhaps I could just brute force my way to it.
And it all started rather promisingly. I learned more than I could have hoped for, and even got good results on the screen, at interactive frame rates.But the quality fell short of what I’d hoped for. And with that, so fell my motivation to work on it. Despite this, I still managed to achieve some rather great things after the initial blog post, namely multiple importance sampling (MIS) and the integration of Nvidia Realtime Denoisers (NRD). Both improving the quality and performance by at least an order of magnitude or two. Almost enough. Almost.
It sucks that I haven’t documented my journey better than I did, as this is the most impressive thing I’ve achieved in a long time. There’s some nice screenshots on my Twitter page, and some short compression-butchered video segments on my Youtube page, but that’s it.
But the reality of it is that the intensive ~two months I worked on the project really burned me out for a long while, despite all the impressive things I achieved. I really enjoyed what I did, but everything has its limits. Though truth be told, RT is perhaps something that I don’t really wish to pursue more. It was very rewarding, but as a concept it’s not really something that interests me that much - I was really only after the results. I thought that simple 2D shadows would be easy to implement with the new technology, but the truth is that they are actually even more complex than 3D ones, at least when implemented the way I approached them. Sunken costs kept me engaged.
But when it comes to using Vulkan as a graphics API, I really did enjoy it a lot. It’s so much nicer than OpenGL, as it’s without all the technical debt of immediate mode rendering and old hardware pipelines, while explicitly supporting all the new things that make development easier and the code more performant, such as pre-compiled shaders and cached pipelines, and multithreaded API design. Though it’s still not easy to use it optimally by any means - especially when it comes to supporting heterogeneous hardware. I already liked OpenGL, and I like Vulkan even more.
A few years back I made yet another version of my unicorn game project - codenamed Unnamed Spacefaring Game: Energized (with modern OpenGL and C#) - and I thought that the code I wrote for it was diamond-grade. Not quite. Or maybe it was, compared to how the previous iterations were implemented on top of a decade+ old Python codebase. I also had big plans for writing the engine side in such a way that it would be able to run efficiently on many-core systems. This wasn’t easy, and it was further complicated by the APIs offered by OpenGL. The solution I arrived on was ambitious, and I feel really bad I never got far enough to really test it in battle.
Vulkan on the other hand has native support for many frames-in-flight and multiple descriptor sets. These features could be used to drastically simplify the resulting architecture, perhaps even completely eliminating the need for all those ambitious inventions I had. I’m very conflicted on how to proceed. Everything sounds almost too simple. Though I guess there’s still some demand for building infrastructure for better multithreading, but the big picture has warped so much that the old plans don’t apply anymore, and I’d have to spend more time planning against that new future to be able to say anything conclusive.
But what I do know is that the code I wrote for that RT Unnamed Building Game was a lot better than that of USGE. I’m really hoping to get back to UBG someday, as its scope is also a lot smaller than USGE’s; if I’d be able to keep the idea alive, yet yeet the RT things, it would be something that could realistically be shipped, and perhaps sold. Though, without RT most of the novelty and graphical appeal wears off…
I guess it’s all about managing scope; it would also be possible to ship a version of USGE with only a few months of development. It would be a technology demo, but a fully playable game nonetheless. But there’s been enough gamedev for now.
Homelab and custom auth
As told above, I had used up (almost every waking moment, I might add) of my summer holiday for learning Vulkan and RT, and there was still a lot to do. Meanwhile at work the then-current project had evaporated over the holiday, and for a moment I was left without one. This gave me the energy to continue learning, but still I faced that eventual burnout. This “opportunity” meant that I could pivot my focus at both work and at my own time to learning about Kubernetes, and forget about all the unconqueable things in ray tracing.
Plus, yet another of my long-time dreams had been to have a solid infrastructure for running self-hosted software - both of my own making, and by other people. And doing it securely. So I didn’t really mind the literal double-timing of learning new things so soon again.
And a lot of new things I learned. It took a bit of iteration, but now I have a somewhat satisfactory hierarchy of Kubernetes manifests, and a small-yet-equally-satisfactory collection of services described by those manifests. All hosted on an ebay’d tinyminimicro-sized server I bought just for this purpose. The server's awesome: it's tiny, x64, and consumes about 6 watts at idle. Pity it has only 8 GB of RAM, and doesn't have the PCI-E connector for a 10+ Gbit network card soldered in. Also, I’d still like to do the manifests over one more time - this time using Terraform for avoiding some repetition on specific parts of the infrastructure. A bit more on that in the next section.
I had hoped to create a VLOG episode about all things homelab, but that didn’t happen this year. But what I instead have is a two-part special about one facet of it - namely authentication and authorization. I’ve materialized a lot of my dreams this year, and the theme continues :)
I set up a monitoring stack with Postgres, Grafana and Prometheus, and migrated some of my own server applications to the new hardware (countdowns, hometab, …). I also set up an instance of changedetection.io. All of these things benefit from unified access control in the form of single sign-on (SSO). As illustrated in the first part of the VLOG, I had initially set up Authelia for this task, but it was not to my satisfaction.
Moonforge
So I did what I do best, and made my own. While this is a bold move even by my standards, I kept things realistic by having Keycloak do the actual user authentication, and having my service continue from that. It’s called Moonforge. All it does is minting and validating JWTs based on configurable policy. There’s more information about this in the second part of the VLOG.
But in short, Authelia felt really nasty because it had a single login cookie for everything. With Moonforge, the user logs in to Keycloak, and then to Moonforge via OIDC, and afterwards to the actual applications with OIDC-like semantics, even if the applications don’t natively support it, thanks to special reverse proxying routes spanning some paths even in each application’s own domain. The JWT cookies for these logins are application-specific, and can’t be used to access other applications unless the user specifically allows it on a case-by-case basis.
I really think that having my own service for auth is for the best - as long as I haven't made a mistake in something elementary. As further detailed in the VLOG, the alternatives are just not that appealing. Authelia requires me to fully trust the applications it protects, and standalone Keycloak is too complex to configure: I’m bound to make a mistake. If I build my own, I know for sure how to configure it. And since I’ve been doing backend stuff for a long time, I hope for everyone’s sake that I’ve learned to build a simple one that is reasonably secure. After all, the harder parts are still done by Keycloak - for now. And I’ve already spent enough time looking for ready-made solutions.
Besides, having an auth(n|z) solution of my own has been yet another long-time aspiration. I think I did some initial UI planning as far back as 2015, and it took until now to implement a system. It looks nothing like originally envisioned, but that is partly due to how the focus so far has been on authz instead of authn. Plus, I haven’t really decided whether I want to let it have its own visual identity, or whether to have a more standardized appearance around my core css.
While the visual identity is a definite nice-to-have, the actual technology behind the scenes is what it’s really all about. In its current form it replaces Authelia with something more secure, without offering much more than that. The foundation I’ve built everything on feels really solid and well grounded. The cookie paths and domain are sensible, and there’s been effort in building everything with a focus on security. There’s extra care in JWT validation, and things like embedded keys and alternative signature algorithms have been explicitly disabled - strange how some JWT libraries don’t even have the option to disable these features. And the small scope has definitely helped.
As I’ve mentioned many times now, for a project of this scope, having Keycloak be part of it is sensible. But I’m hoping to find the time to replace it with my own implementation. When I was still working on Tracker, I implemented a login flow similar to how for example WhatsApp Web works now. That type of passwordless flow was really nice, and I’ve wanted to replicate it in a more generic setting, while also adding some other security features. Hence the dream. In the VLOG I talk about all the things I’d like to add and how they’d strengthen the security of all the services relying on the system - pushing more and more of the auth functionality on to better trusted companion devices, outside the device and the server the login is being performed on. There's also plans to harden the surface which mints the JWTs by requiring input from a trusted device. I’d also like to get hands-on experience interfacing with security keys such as Yubikeys.
Moonforge is far from being feature-complete, but it’s perfectly serviceable for its current task. I feel good, and with that 'final part of the 1st stage' of my Kubernetes infrastructure implemented, I now have what I wanted: a stable foundation for hosting and building self-hosted services and applications. Next up is Terraform, better uptime monitoring, perhaps distributed logging and most importantly improved machine-to-machine authentication. And maybe even making more VLOGs on the topic.
Terraform, cloud and static HTML generation
With the things at home looking so good now, why stop there? The next thing I could be improving is my (still perfectly functioning) decade+ old homepage. The current site is hosted on a single server, and the PHP in it dynamically serves WikiCreole-based content. I’ve been meaning to replace it for the past two years with static generation and geo-replicated hosting, but the time hasn’t been ripe. Except now*.
There’s been demand at work to learn more about the cloud, and I was able to use this to my advantage. I was required to set up a static website on AWS S3 and CloudFront, so why not use what I learned for the new site? And while at it, why not do it properly. This is again a topic that would have made a great VLOG episode or a post of its own, but I’ll try to be brief.
At work I was given Terraform to accomplish the task, and I quickly fell in love with it. It allows for writing all the infrastructure as “code”, a bit similiar to how Kubernetes manifests work; precise and to some degree self-documenting. And making changes is easy, as the user doesn’t have to know the exact commands, they only need to tell how they want the end result to look like. It’s a really nice way to work.
The best advanced feature of Terraform are the “modules”, which allow for defining complex reusable components, which in turn expand to a set of simpler pieces of infrastructure. While that’s an overkill for just a single static website, I’m looking forward to migrating all(?) my Kubernetes manifests to Terraform. While raw manifests are mostly fine, the biggest pain point for me has been in defining firewall rules and HTTP(S) ingresses. These are very verbose, and contain a lot of dupliction between each other. With Terraform I should be able to write a single custom utu_http_ingress module, which defines all those at once. There’s also some special additions that need to be done to each Traefik (the reverse proxy) HTTP ingress route entry in order to support the special login paths needed by Moonforge - having the module transparently do this in a centrally defined location is awesome.
With the basic infra up, the more fun part was uploading the content. I could have used some type of shell script and aws-cli to upload the site content, but it turned out to be really easy to use the SDK and build my own program. With it I could easily incorporate some extra steps, such as only uploading the files that have been changed / renamed between each run, and more importantly transforming the uploaded filenames and paths. The static site generator includes the .html file extension on all content, and I was trivially able to remove that. There was also some special logic on how “index” pages and paths worked with the PHP site, and I was able to take that into account, too.
And lastly, I learned that CloudFront is able to compress the content it serves, but this feature depends on the file types and the available CPU time on each edge server. The only way I can ensure that the content is always served compressed is to save it pre-compressed to S3, and then return Content-Encoding header with the correct value for each request. But now that I control the upload process, this was no problem :)
And speaking of content, that’s a topic for another post, again. A few years back I stumbled on statiq, and found it to be the least-sucking tool in the .NET world, so that’s what I chose and started to slowly port over the site itself, and the content. Instead of WikiCreole and PHP I had Markdown and C# HTML compiled down to plain HTML.
With this new technology stack I could also accomplish some of my long-time desires for ever so slightly improving content-discoverability on the site. Along with the old stuff, the site also serves as the companion for my VLOG, containing the scripts, some technical specs and other commentary on each episode. I wanted to make it easier to move between different episodes and projects, so I implemented a sidebar navigator for this.

Site generation in statiq is a multi-stage process, with one of the stages being content discovery and “front-matter” parsing. This way each page knows what other pages exist, and I’m able to pull similar pages from the metadata to the sidebar - either by the folder structure, or by a special grouping key. This metadata is also used to build navigation breadcrumbs.

*The tool still sucks, though. It tries so hard, but fails. There’s a live-reload server for avoiding full rebuilds when working on individual pages and templates, and a caching system so that those full rebuilds can be avoided also when publishing. Unfortunately, both have been broken for several years. The live reload server needs to be restarted whenever a page containing an error is opened (so don’t save a live-reload page until the code compiles!), and the caching system doesn’t purge the metadata cache, so pages appear multiple times in it, breaking the sidebar.
I was going to sidestep all that by making a hot-reload system of my own, by building on the “hot” reload technology I invented for USGE and UBG and UBG's asset pipeline. Newer dotnet supports unloadable assemblies once again, so it’s possible to keep the compiler and dependencies loaded in memory, but still dynamically reload all the user code - a sub-second operation. That way I could delete the cache between rounds, and avoid the server dying whenever an error occurs, by simply very quickly restarting it after each run instead. Unfortunately statiq always starts a text-based debug console meant for live-reload even when not using it, and never cleans it when exiting, thereby failing to run again in the same process. The relatively complex code which does some high-level orchestration of the generator is rather tightly coupled with the code controlling the debug console, so it’s not an easy task to separate these two. Even cleaning up afterwards is not trivial. FML.
Despite this, the preview for the new site is live, and the DX is a bit better than before. And it’ll get better, won’t it? And if not, I’ll just have to make my own generator. There’s still work to be done in upgrading imagepaste, perhaps the contact form, and transferring over some other static content. I’d also like to improve the page load latency, so I’ll have to find a way to cache the CSS file, yet reliably invalidate it without rebuilding the whole static site. That might be impossible to do without scripting. But for now, at least the primary content has been migrated succesfully.
Minecraft and Lua
It’s been a tight year, and I wanted to take my mind off other things, so I found myself gravitating towards modded Minecraft once again. Plus, it’s just so damn addictive it’s hard to keep away for too long.
This time I’ve been playing Create: Above and Beyond, a non-expert modpack with strong progression. The focus is on Create, a “low-tech” automation mod, which has large moving machinery which in my opinion fits the theme of Mincraft really well. As the technology level keeps increasing over the playthrough, some products benefit from automating them with programmable in-game computers. It’s also fun to monitor some production chains, such as the amount of charcoal fuel.
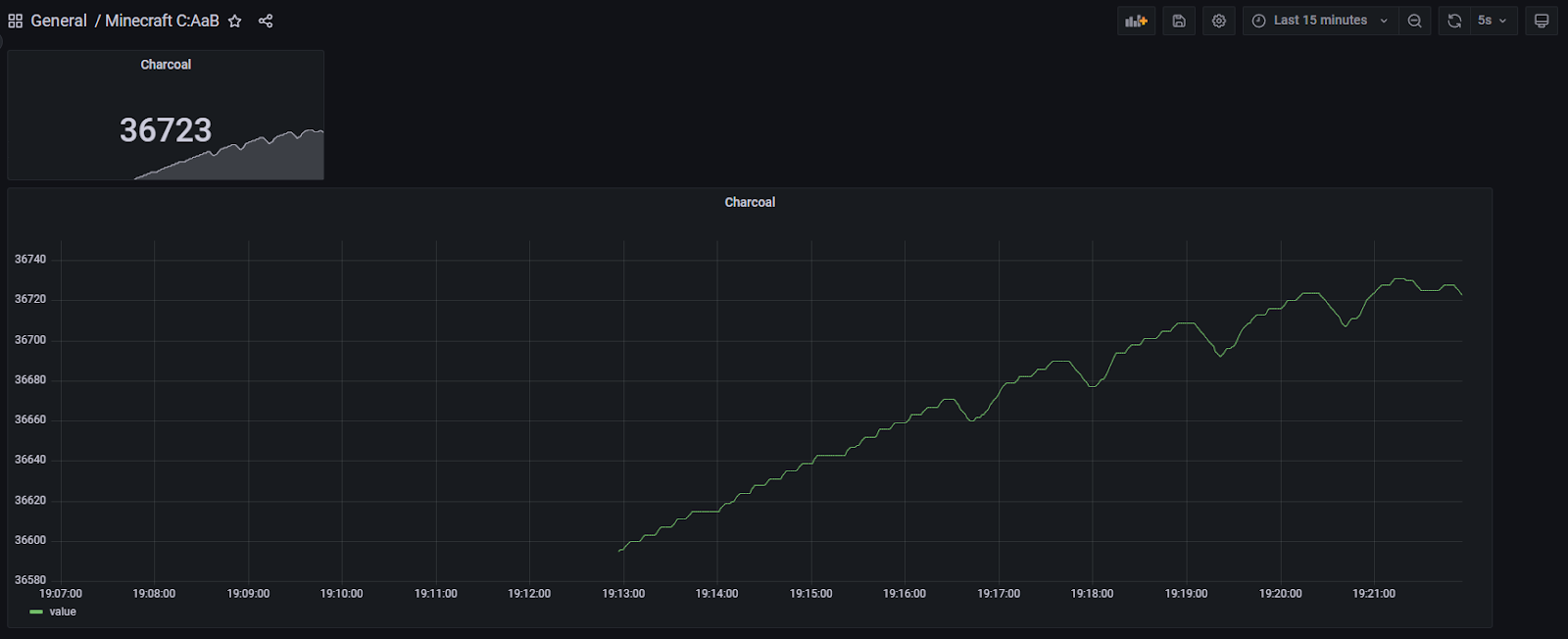
Few years ago I already built some libraries for saving metrics to Postgres (with plans to migrate to TimescaleDB), so this time I was able to build an in-game Lua program, a metrics gateway server and a Grafana dashboard in two short hours :) This was a good primer for the more complex factory-controlling programs.
While the modpack is heavily focused on doing things with just Create, some things would get needlessly complicated when done with just in-world redstone circuits. Just like I really enjoyed describing infrastructure with Terraform, I also enjoyed avoiding complex circuits with Lua code. It’s a lot more self-documenting, and the code itself is creeper-proof :p Some might argue that the beauty of the game is using those simpler primitives for achieving the end goal, but at some point it just becomes plain frustrating. Though in this case I’m not very good with Lua, and I’m not even trying to be: I know the bare minimum, and use that to make the programs. I guess that’s my way of playing the same game.
And as it was beautifully noted to me, I guess I’m in the right industry when even relaxing and playing video games leads me back to writing code. Or alternatively, I’m just a sick and troubled mind, which can’t ever truly let go and just relax (:
Closing words
Whoa. It seems I’ve been really active this year. Maybe too much so. But, for now my only real regret is that I haven’t documented my doings even better. This post ended up a lot longer than I first anticipated trying to cover even the majority of what I’ve done. Especially the gamedev things. But at least I have something to show for it, and I did at least try with Twitter.
Thanks for reading! If you are - for some strange reason - after for even more to read, can I recommend you the 15 year anniversary post of the blog. It’s a lot shorter, I promise!
PS. I’m also working on a little something to highlight all the wonderful private code commits of mine, and also my other online doings in a central place. Stay tuned.